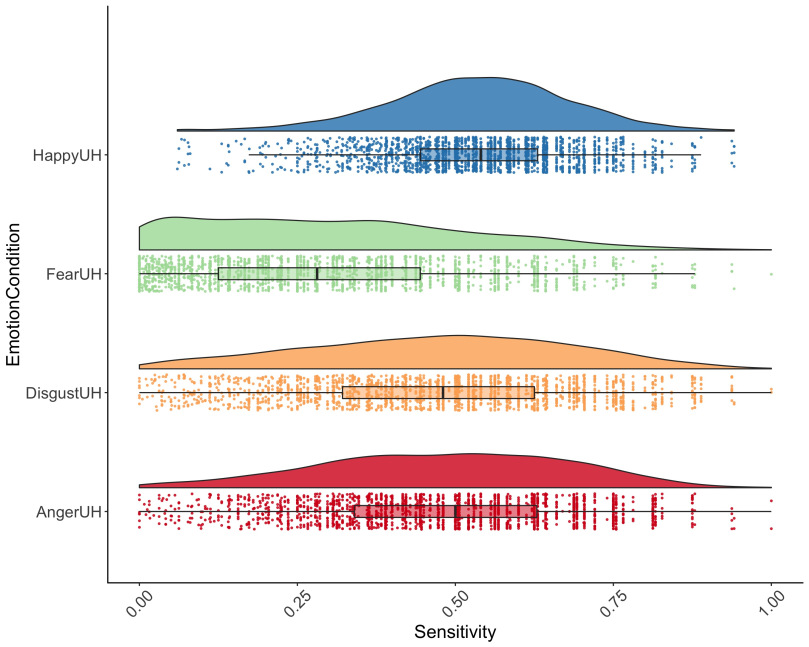
Introducing Raincloud Plots!
Like many of you, I love ggplot2. The ability to make beautiful, informative plots quickly is a major boon to my research workflow. One plot I’ve been particularly fond of recently is the ‘violin + boxplot + jittered dataset’ combo, which nicely provides an overview of the raw data, the probability distribution, and ‘statistical inference…