- A gut, heart, and breath check: what matters most for cognition?

Last week I asked twitter a question that comes up frequently in our lab: what visceral rhythm exerts the most impact on cognition [1]? Now, this is a question which is deliberately vague in nature. The goal is to force a ‘gut check’ on which visceral systems that we, as neuroscientists, might reasonably expect to bias cognition. What do I mean by cognition? Literally any aspect of information processing. Perception, memory, learning, emotion, pain, you name it. Some of you jokingly pointed out that if any of these rhythms cease entirely (e.g., in death), cognition will surely be impacted. So to get a bit closer to an experimental design which might build on these intuitions, I offered the following guidelines:
Yeah, baseline assumption of the question is all are actually functioning in a living person. E.g., “presenting a stimulus or condition at a different phase of the heart/stomach/respiration” would exert the greatest effect.
— Micah Allen (@micahgallen) February 15, 2020
I.e., what I largely had in mind was the kinds of psychophysiology experiments that are currently in vogue – presenting stimuli during different phases of a particular visceral cycle, and then interpreting differences in reaction time, accuracy, subjective response, or whatever as evidence of ‘brain-body interaction’. Of course, these are far from the only ways in which we can measure the influence of the body on the brain, and I intentionally left the question as open as possible. I wanted to know: what are your ‘gut feelings’, about gut feelings? And the twitter neuroscience community answered the call!
poll_responses.jpg
Which visceral rhythm do you think exerts the most influence on cognition?
— Micah Allen (@micahgallen) February 15, 2020
Here you can see that overall, respiration was a clear winner, and was also my own choice. Surprisingly, gastric rhythms just beat out cardiac, at about 29 vs 27.5%. More on this later. Roughly 380/1099 respondent’s felt that, all else being equal, respiration was likely to produce the most influence on cognition. And I do agree; although the literature is heavily biased in terms of numbers of papers towards the cardiac domain, intuitively respiration feels like a better candidate for the title of heavy-weight visceral rhythm champion.
Why is that? At least a few reasons spring to mind. For one thing, the depth and frequency of respiration directly modulates heart-rate variability, through basic physiological reflexes such as the respiratory sinus arrhythmia. At a more basic level still, respiration is of course responsible for gas exchange and pH regulation, conditioning the blood whose transport around the body depends upon the heart. That is to say; the heart is ultimately the chauffeur for the homeostatic function of the lungs, always second fiddle.
In the central nervous system both systems matter in a big way of course, and are closely tied to one another. A lesion to the brain-stem that results in cardiac or respiratory arrest is equally deadly, and the basic homeostatic clocks that control these rhythms are tightly interwoven for good reason.
But here, one can reasonably argue that these low-level phenomenon don’t really speak to the heart of the question, which is about (‘higher-order’) cognition. What can we say about that? Neuroviscerally speaking, in my opinion the respiratory rhythm has the potential to influence a much broader swath of brain areas. Respiration reaches the brain through multiple pathways: bypassing the limbic system altogether to target the prefrontal cortex via the innervation of the nasal septum, through basic somatosensory entrainment via the mechanical action of the lungs and chest wall, and through the same vagally mediated pathways as those carrying baroreceptive information from the heart. In fact, the low level influence of respiration on the heart means that the brain can likely read-out or predict heart-rate at least partially from respiration alone, independently of any afferent baro-receptor information (that is of course, speculation on my part). I think Sophie Betka’s response captures this intuition beautifully:
I used to think cardiac but now working on breathing, I would say1)Breathing 2)Cardiac/gastric. Breathing control has this beauty to be both autonomic and somatic.I know you ask for visceral rhythm but voluntary -as spontaneous-breathing will also modulate afferences & cognition
— Sᴏᴘʜɪᴇ Bᴇᴛᴋᴀ (@DoctoresseSoso) February 15, 2020
All of which is to say, that respiration affords many potential avenues by which to bias, influence, or modulate cognition, broadly speaking. Some of you asked whether my question was more aimed at “the largest possible effect size” or the “most generalized effect size”. This is a really important question, which again, I simply intended to collapse across in my poll, whose main purpose was to generate thought and discussion. An it really is a critical issue for future research; we might predict that cardiac or gastric signals would modulate very strong effects in very specific domains (e.g., fear or hunger), but that respiration might effect weak to moderate effects in a wide variety of domains. Delineating this difference will be crucial for future basic neuroscience, and even more so if these kinds of effects are to be of clinical significance.
Suffice to say, I was pleased to see a clear majority agree that respiration is the wave of the future (my puns on the other hand, are likely growing tiresome). But I was surprised to see the strong showing of the gastric rhythm, relative to cardiac. My internal ranking was definitely leaning towards 1) respiration, 2) cardiac, 3) gastric. My thinking here was; sure, the brain may track the muscular contractions of the stomach and GI tract, but is this really that relevant for any cognitive domain other than eating behavior? To be fair, I think many respondents probably did not consider the more restricted case of, for example, presenting different trials or stimuli at gastric contraction vs expansion, but interpreted the question more liberally in terms of hormone excretion, digestion, and possibly even gut micobiome or enteric-nervous linked effects. And that is totally fair I think; taken as a whole, the rhythm of the stomach and gut is likely to exert a huge amount of primary and secondary effects on cognition. This issue was touched on quite nicely by my collaborator Paul Fletcher:
Seems to me that it depends on the time-scale we’re interested in. Gastric offers very low frequency signals (e.g. ghrelin) plus some higher-freq (e.g. intrinsic contractility) while I think that, in the main, cardio-respiratory are more rapidly-changing (with some exceptions).
— Paul Fletcher (@PaulPcf22) February 15, 2020
I think that is absolutely right; to a degree, how we answer the question depends exactly on which timescales and contexts we are interested in. It again raises the question of: what kind of effects are we most interested in? Really strong but specific, or weaker, more general effects? Intuitively, being hungry definitely modulates the gastric rhythm, and in turn we’ve all felt the grim specter of ‘hanger’ causing us to lash out at the nearest street food vendor.
Forgetting these speedy bodily ‘rabbits’ all together, what about those most slow of bodily rhythms [3]. Commenters Andrea Poli, Anil Seth, and others pointed out that at the very slowest timescales, hormonal and circadian rhythms can regulate all others, and the brain besides:
Given the amount of 5HT produced by the GI tract and the gut-brain connections, my guess would be that the GI function has the greatest influence. But I fear that that was the answer you expected and you are ready to prove us wrong in one next tweet
— Andrea Polli (@LANdreaSS) February 15, 2020
For my money it’s definitely the circadian rhythm. Which, perhaps surprisingly, does indeed have visceral involvement.
— Anil Seth (@anilkseth) February 16, 2020
Indeed, if we view these rhythms as a temporal hierarchy (as some authors have argued), then it is reasonable to assume that causality should in general flow from the slowest, most general rhythms ‘upward’ to the fastest, most specific rhythms (i.e., cardiac, adrenergic, and neural). And there is definitely some truth to that; the circadian rhythm causes huge changes in baseline arousal, heart-rate variability, and even core bodily temperature. In the end, it’s probably best to view each of these smaller waves as inscribed within the deeper, slower waves; their individual shape may vary depending on context, but their global amplitude comes from the depths below. And of course, here the gloomy ghost of circular causality raises its incoherent head; because these faster rhythms can in turn regulate the slower, in a never ceasing allostatic push-me-pull-you affair.
All that considered, is is perhaps unsurprising then that in this totally unscientific poll at least, the gastric rhythm rose to challenge the all-mighty cardiac [2]. It seems clear that the preponderance of cardiac-brain studies is more an artifact of ease of study, rather than a deep seated engagement with their predominance. And ultimately, if we want to understand how the body shapes the mind, we will need to take precisely the multi-scale view espoused by many commenters.
A final thought on what kinds of effects might matter most: of all of these rhythms, only one is directly amenable to conscious control. That is of course, the breath. And it is intriguing also that across many cultural practices – elite sportsmanship, martial arts, meditation, and marksmanship for example – the regulation of the breath is taught as a core technique for altering awareness, attention, and mood. I think for this reason, respiration is among the most interesting of all possible rhythms. It sits at that rare precipice, teetering between fully automatic and fully conscious. Our ability to become conscious of the breath can be a curse and a gift; many of you may feel a slight anxiety as you read this article, becoming ever so slightly more aware of your own rising and falling breath [4]. From the point of view of neuropsychiatry, I can’t help but feel like whatever the effects of respiration are, this amenability to control, and the possibility to regulate all other rhythms in turn, makes understanding the breath an absolutely critical focus for clinical translation.
Footnotes:
[1] Closely related to the question I am mostly commonly asked in talks: what effect size do you expect in general for cardiac/respiratory/gastric-brain interaction?[2] I do apologize for the misleading usage of a poop emoji to signify the gastric rhythm. Although poop is certainly a causal product of the gastric rhythm, I did not mean to imply a stomach full of it.
[3] Regrettably, all of these rhythms would have been subsided in the general response category of ‘other’. This likely greatly suppressed their response rates, but I think we can all forgive this limitation of a deeply unscientific intuition pump poll.
[4] And that is something which seems to uniquely define the body in general; usually absent, potentially unpleasant (or very pleasant) when present. Phenomenologists call this the ‘transparency’ of the body-as-subject.
Header image credit:
Andrea Castelletti
- Introducing Raincloud Plots!
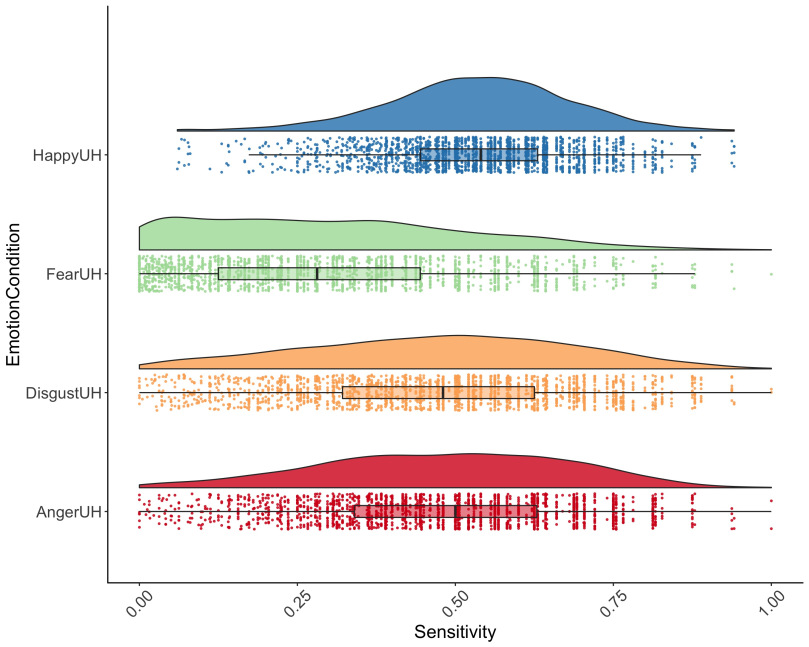
Like many of you, I love ggplot2. The ability to make beautiful, informative plots quickly is a major boon to my research workflow. One plot I’ve been particularly fond of recently is the ‘violin + boxplot + jittered dataset’ combo, which nicely provides an overview of the raw data, the probability distribution, and ‘statistical inference at a glance’ via medians and confidence intervals. However, as pointed out in this tweet by Naomi Caselli, violin plots mirror the data density in a totally uninteresting/uninformative way, simply repeating the same exact information for the sake of visual aesthetic. Not to mention, for some at least they are actually a bit lewd. In my quest for a better plot, which can show differences between groups or conditions while providing maximal statistical information, I recently came upon the ‘split violin’ plot. This nicely deletes the mirrored density, freeing up room for additional plots such as boxplots or raw data. Inspired by a particularly beautiful combination of split-half violins and dotplots, I set out to make something a little less confusing. In particular, dot plots are rather complex and don’t precisely mirror what is shown in the split violin, possibly leading to more confusion than clarity. Introducing ‘elephant’ and ‘raincloud’ plots, which combine the best of all worlds! Read on for the full code-recipe plus some hacks to make them look pretty (apologies for poor markup formatting, haven’t yet managed to get markdown to play nicely with wordpress)!
Let’s get to the data – with extra thanks to @MarcusMunafo, who shared this dataset on the University of Bristol’s open science repository.
First, we’ll set up the needed libraries and import the data:
library(readr)
library(tidyr)
library(ggplot2)
library(Hmisc)
library(plyr)
library(RColorBrewer)
library(reshape2)source(“https://gist.githubusercontent.com/benmarwick/2a1bb0133ff568cbe28d/raw/fb53bd97121f7f9ce947837ef1a4c65a73bffb3f/geom_flat_violin.R”)
my_data<-read.csv(url("https://data.bris.ac.uk/datasets/112g2vkxomjoo1l26vjmvnlexj/2016.08.14_AnxietyPaper_Data%20Sheet.csv"))
head(X)
Although it doesn’t really matter for this demo, in this experiment healthy adults recruited from MTurk (n = 2006) completed a six alternative forced choice task in which they were presented with basic emotional expressions (anger, disgust, fear, happiness, sadness and surprise) and had to identify the emotion presented in the face. Outcome measures were recognition accuracy and unbiased hit rate (i.e., sensitivity).
For this demo, we’ll focus on the unbiased hitrate for anger, disgust, fear, and happiness conditions. Let’s reshape the data from wide to long format, to facilitate plotting:
library(reshape2)
my_datal <- melt(my_data, id.vars = c("Participant"), measure.vars = c("AngerUH", "DisgustUH", "FearUH", "HappyUH"), variable.name = "EmotionCondition", value.name = "Sensitivity")head(my_datal)
Now we’re ready to start plotting. But first, lets define a theme to make pretty plots.
raincloud_theme = theme(
text = element_text(size = 10),
axis.title.x = element_text(size = 16),
axis.title.y = element_text(size = 16),
axis.text = element_text(size = 14),
axis.text.x = element_text(angle = 45, vjust = 0.5),
legend.title=element_text(size=16),
legend.text=element_text(size=16),
legend.position = “right”,
plot.title = element_text(lineheight=.8, face=”bold”, size = 16),
panel.border = element_blank(),
panel.grid.minor = element_blank(),
panel.grid.major = element_blank(),
axis.line.x = element_line(colour = ‘black’, size=0.5, linetype=’solid’),
axis.line.y = element_line(colour = ‘black’, size=0.5, linetype=’solid’))Now we need to calculate some summary statistics:
lb <- function(x) mean(x) – sd(x)
ub <- function(x) mean(x) + sd(x)sumld<- ddply(my_datal, ~EmotionCondition, summarise, mean = mean(Sensitivity), median = median(Sensitivity), lower = lb(Sensitivity), upper = ub(Sensitivity))
head(sumld)
Now we’re ready to plot! We’ll start with a ‘raincloud’ plot (thanks to Jon Roiser for the great suggestion!):
g <- ggplot(data = my_datal, aes(y = Sensitivity, x = EmotionCondition, fill = EmotionCondition)) +
geom_flat_violin(position = position_nudge(x = .2, y = 0), alpha = .8) +
geom_point(aes(y = Sensitivity, color = EmotionCondition), position = position_jitter(width = .15), size = .5, alpha = 0.8) +
geom_boxplot(width = .1, guides = FALSE, outlier.shape = NA, alpha = 0.5) +
expand_limits(x = 5.25) +
guides(fill = FALSE) +
guides(color = FALSE) +
scale_color_brewer(palette = “Spectral”) +
scale_fill_brewer(palette = “Spectral”) +
coord_flip() +
theme_bw() +
raincloud_themeg
I love this plot. Adding a bit of alpha transparency makes it so we can overlay boxplots over the raw, jittered data points. In one https://blogs.scientificamerican.com/literally-psyched/files/2012/03/ElephantInSnake.jpegplot we get basically everything we need: eyeballed statistical inference, assessment of data distributions (useful to check assumptions), and the raw data itself showing outliers and underlying patterns. We can also flip the plots for an ‘Elephant’ or ‘Little Prince’ Plot! So named for the resemblance to an elephant being eating by a boa-constrictor:
g <- ggplot(data = my_datal, aes(y = Sensitivity, x = EmotionCondition, fill = EmotionCondition)) +
geom_flat_violin(position = position_nudge(x = .2, y = 0), alpha = .8) +
geom_point(aes(y = Sensitivity, color = EmotionCondition), position = position_jitter(width = .15), size = .5, alpha = 0.8) +
geom_boxplot(width = .1, guides = FALSE, outlier.shape = NA, alpha = 0.5) +
expand_limits(x = 5.25) +
guides(fill = FALSE) +
guides(color = FALSE) +
scale_color_brewer(palette = “Spectral”) +
scale_fill_brewer(palette = “Spectral”) +coord_flip() +
theme_bw() +
raincloud_themeFor those who prefer a more classical approach, we can replace the boxplot with a mean and confidence interval using the summary statistics we calculated above. Here we’re using +/- 1 standard deviation, but you could also plot the SEM or 95% CI:
g <- ggplot(data = my_datal, aes(y = Sensitivity, x = EmotionCondition, fill = EmotionCondition)) +
geom_flat_violin(position = position_nudge(x = .2, y = 0), alpha = .8) +
geom_point(aes(y = Sensitivity, color = EmotionCondition), position = position_jitter(width = .15), size = .5, alpha = 0.8) +
geom_point(data = sumld, aes(x = EmotionCondition, y = mean), position = position_nudge(x = 0.3), size = 2.5) +
geom_errorbar(data = sumld, aes(ymin = lower, ymax = upper, y = mean), position = position_nudge(x = 0.3), width = 0) +
expand_limits(x = 5.25) +
guides(fill = FALSE) +
guides(color = FALSE) +
scale_color_brewer(palette = “Spectral”) +
scale_fill_brewer(palette = “Spectral”) +
theme_bw() +
raincloud_themeg
Et voila! I find that the combination of raw data + box plots + split violin is very powerful and intuitive, and really leaves nothing to the imagination when it comes to the underlying data. Although here I used a very large dataset, I believe these would still work well for more typical samples sizes in cognitive neuroscience (i.e., N ~ 30-100), although you may want to only include the boxplot for very small samples.
I hope you find these useful, and you can be absolutely sure they will be appearing in some publications from our workbench as soon as possible! Go forth and make it rain!
Thanks very much to @naomicaselli, @jonclayden, @patilindrajeets, & @jonroiser for their help and inspiration with these plots!
- OKCupid Data Leak – Framing the Debate
You’ve probably heard by now that a ‘researcher’ by the name of Emil Kirkegaard released the sensitive data of 70,000 individuals from OKCupid on the Open Science framework. This is an egregious violation of research ethics and we’re already beginning to see mainstream media coverage of this unfolding story. I’ve been following this pretty closely as it involves my PhD alma mater Aarhus University. All I want to do here is collect relevant links and facts for those who may not be aware of the story. This debacle is likely going become a key discussion piece in future debates over how to conduct open science. Jump to the bottom of this post for a live-updated collection of news coverage, blogs, and tweets as this issue unfolds.
Emil himself continues to fan flames by being totally unapologetic:
@tranquileye If you don’t want other people to see things, don’t post them publicly on the Internet. OKCupid does feature private answering.
— Emil OW Kirkegaard (@KirkegaardEmil) May 13, 2016
@jetsumgerl Let’s wait until the SJW-storm is over and talk about it.
— Emil OW Kirkegaard (@KirkegaardEmil) May 11, 2016
An open letter has been formed here, currently with the signatures of over 150 individuals (myself included) petitioning Aarhus University for a full statement and investigation of the issue:
Meanwhile Aarhus University has stated that Emil acted without oversight or any affiliation with AU, and that if he has claimed otherwise they intend to take (presumably legal) action:
1/2 Aarhus University states the following regarding #OKcupid: The views and actions by student Emil Kirkegaard is not on behalf of AU …
— Aarhus Universitet (@AarhusUni) May 12, 2016
2/2 … his actions are entirely his own responsibility. If @AarhusUni’s name has been misused, we will take action.
— Aarhus Universitet (@AarhusUni) May 12, 2016
I’m sure a lot more is going to be written as this story unfolds; the implications for open science are potentially huge. Already we’re seeing scientists wonder if this portends previously unappreciated risks of sharing data:
This is why I am v cautious of calls for open data @OSFramework https://t.co/xcBQlqOiOW
— Antonia Hamilton (@antoniahamilton) May 13, 2016
I just want to try and frame a few things. In the initial dust-up of this story there was a lot of confusion. I saw multiple accounts describing Emil as a “PI” (primary investigator), asking for his funding to be withdrawn, etc. At the time the details surrounding this was rather unclear. Now as more and more emerge it seems to paint a rather different picture, which is not being accurately portrayed so far in the media coverage:
Emil is not a ‘researcher’. He acted without any supervision or direct affiliation to AU. He is a masters student who claims on his website that he is ‘only enrolled at AU to collect SU [government funds])’. I’m seeing that most of the outlets describe this as ‘researchers release OKCupid data’. When considering the implications of this for open science and data sharing, we need to frame this as what it is: a group of hacktivists exploiting a security vulnerability under the guise of open science. NOT a university-backed research program.
What implications does this have for open science? From my perspective it looks like we need to discuss the role oversight and data protection. Ongoing twitter discussion suggests Emil violated EU data protection laws and the OKCupid terms of service. But other sources argue that this kind of scraping ‘attack’ is basically data-gathering 101 and that nearly any undergraduate with the right education could have done this. It seems like we need to have a conversation about our digital rights to data privacy, and whether those are doing enough to protect us. Doesn’t OKCupid itself hold some responsibility for allowing this data be access so easily? And what is the responsibility of the Open Science Foundation? Do we need to put stronger safeguards in place? Could an organization like anonymous, or even ISIS, ‘dox’ thousands of people and host the data there? These are extreme situations, but I think we need to frame them now before people walk away with the idea that this is an indictment of data sharing in general.
Below is a collection of tweets, blogs, and news coverage of the incident:
Tweets:
Brian Nosek on the Open Science Foundations Response:
Initial step for OKCupid data release on @OSFramework. @KirkegaardEmil password protected user datafile, version history is now inaccessible
— Brian Nosek (@BrianNosek) May 12, 2016
More tweets on larger issues:
@neuroconscience Protection of personal data is left, right and center of open science discussions with special sessions at meetings…
— Björn Brembs (@brembs) May 13, 2016
@neuroconscience also: dangerous to call someone a hacker who accessed info that they were “allowed” to access: remember Aaron Schwartz
— Richard D. Morey (@richarddmorey) May 13, 2016
@neuroconscience 1) because OSF doesn’t check all postings manually; 2) because that’s how HTML works, unfortunately
— Richard D. Morey (@richarddmorey) May 13, 2016
Emil has stated he is not acting on behalf of AU:
@neuroconscience as he has stated herehttps://t.co/ZrUmD932o3https://t.co/8ytnzbQ0ylhttps://t.co/HGliDdERgs
— Karsten Olsen (@karsolsen) May 13, 2016
News coverage:
Vox:
Motherboard:
http://motherboard.vice.com/read/70000-okcupid-users-just-had-their-data-published
ZDNet:
http://www.zdnet.com/article/okcupid-user-accounts-released-for-the-titillation-of-the-internet/
Forbes:
http://www.themarysue.com/okcupid-profile-leak/
Here is a great example of how bad this is; Wired runs stury with headline ‘OKCupid study reveals perils of big data science:
OkCupid Study Reveals the Perils of Big-Data Science
- Is Frontiers in Trouble?

Lately it seems like the rising tide is going against Frontiers. Originally hailed as a revolutionary open-access publishing model, the publishing group has been subject to intense criticism in recent years. Recent issues include being placed on Beall’s controversial ‘predatory publisher list‘, multiple high profile disputes at the editorial level, and controversy over HIV and vaccine denialist articles published in the journal seemingly without peer review. As a proud author of two Frontiers articles and former frequent reviewer, these issues compounded with a general poor perception of the journal recently led me to stop all publication activities at Frontiers outlets. Although the official response from Frontiers to these issues has been mixed, yesterday a mass-email from a section editor caught my eye:
Dear Review Editors, Dear friends and colleagues,
As some of you may know, Prof. Philippe Schyns recently stepped down from his role as Specialty Chief Editor in Frontiersin Perception Science, and I have been given the honor and responsibility of succeeding him into this function. I wish to extend to him my thanks and appreciation for the hard work he has put in building this journal from the ground up. I will strive to continue his work and maintain Frontiers in Perception Science as one of the primary journals of the field. This task cannot be achieved without the support of a dynamic team of Associate Editors, Review Editors and Reviewers, and I am grateful for all your past, and hopefully future efforts in promoting the journal.
It am aware that many scientists in our community have grown disappointed or even defiant of the Frontiers publishing model in general, and Frontiers in Perception Science is no exception here. Among the foremost concerns are the initial annoyance and ensuing disinterest produced by the automated editor/reviewer invitation system and its spam-like messages, the apparent difficulty in rejecting inappropriate manuscripts, and (perhaps as a corollary), the poor reputation of the journal, a journal to which many authors still hesitate before submitting their work. I have experienced these troubles myself, and it was only after being thoroughly reassured by the Editorial office on most of these counts that I accepted to get involved as Specialty Chief Editor. Frontiers is revising their system, which will now leave more time for Associate Editors to mandate Review Editors before sending out automated invitations. When they occur, automated RE invitations will be targeted to the most relevant people (based on keyword descriptors), rather than broadcast to the entire board. This implies that it is very important for each of you to spend a few minutes editing the Expertise keywords on your Loop profile page. Most of these keywords were automatically collected within your publications, and they may not reflect your true area of expertise. Inappropriate expertise keywords are one of the main reasons why you receive inappropriate reviewing invitations! In the new Frontiers system, article rejection options will be made more visible to the handling Associate Editor. Although my explicit approval is still required for any manuscript rejection, I personally vow to stand behind all Associate Editors who will be compelled to reject poor-quality submissions. (While perceived impact cannot be used as a rejection criterion, poor research or writing quality and objective errors in design, analysis or interpretation can and should be used as valid causes for rejection). I hope that these measures will help limit the demands on the reviewers’ time, and contribute to advancing the standards and reputation of Frontiers in Perception Science. Each of you can also play a part in this effort by continuing to review articles that fall into your area of expertise, and by submitting your own work to the journal.
I look forward to working with all of you towards establishing Frontiers in Perception Science as a high-standard journal for our community.
It seems Frontiers is indeed aware of the problems and is hoping to bring back wary reviewers and authors. But is it too little too late? Discussing the problems at Frontiers is often met with severe criticism or outright dismissal by proponents of the OA publishing system, but I felt these neglected a wider negative perception of the publisher that has steadily grown over the past 5 years. To get a better handle on this I asked my twitter followers what they thought. 152 persons responded as follows:
Frontiers says they are “revising their [review] system”. Do you feel Frontiers has a serious quality problem?
— Micah Allen (@neuroconscience) January 14, 2016
As some of you requested control questions, here are a few for comparison:
As requested, a control question: Do you feel PLOS ONE has a serious quality problem?
— Micah Allen (@neuroconscience) January 15, 2016
That is a stark difference between the two top open access journals – whereas only 19% said there was no problem at Frontiers, a full 50% say there is no problem at PLOS ONE. I think we can see that even accounting for general science skepticism, opinions of Frontiers are particularly negative.
Sam Schwarzkopf also lent some additional data, comparing the whole field of major open access outlets – Frontiers again comes out poorly, although strangely so does F1000:
Which broad-scale open science journal do you think publishes the lowest quality papers? @lakens @neuroconscience
— Sam Schwarzkopf (@sampendu) January 15, 2016
These data confirm what I had already feared: public perception among scientists (insofar as we can infer anything from such a poll) is lukewarm at best. Frontiers has a serious perception problem. Only 19% of 121 respondents were willing to outright say there was no problem at the journal. A full 45% said there was a serious problem, and 36% were unsure. Of course to fully evaluate these numbers, we’d like to know the baserate of similiar responses for other journals, but I cannot imagine any Frontiers author, reviewer, or editor feeling joy at these numbers – I certainly do not. Furthermore they reflect a widespread negativity I hear frequently from colleagues across the UK and Denmark.
What underlies this negative perception? As many proponents point out, Frontiers has been actually quite diligent at responding to user complaints. Controversial papers have been put immediately under review, overly spammy-review invitations and special issue invites largely ceased, and so on. I would argue the issue is not any one single mistake on the part of Frontiers leadership, but a growing history of errors contributing to a perception that the journal is following a profit-led ‘publish anything’ model. At times the journal feels totally automated, within little human care given to publishing and extremely high fees. What are some of the specific complaints I regularly hear from colleagues?
Spammy special issue invites. An older issue, but at Frontier’s inception many authors were inundated with constant invites to special issues, many of which were only tangentially related to author’s specialties.
Spammy review invites. Colleagues who signed on to be ‘Review Editors’ (basically repeat reviewers) reported being hit with as many as 10 requests to review in a month, again many without relevance to their interest
Related to both of the above, a perception that special issues and articles are frequently reviewed by close colleagues with little oversight. Similiarly, many special issues were edited by junior researchers at the PhD level.
Endless review. I’ve heard numerous complaints that even fundamentally flawed or unpublishable papers are impossible or difficult to reject. Reviewers report going through multiple rounds of charitable review, finding the paper only gets worse and worse, only to be removed from the review by editors and the paper published without them.
Again, Frontiers has responded to each of these issues in various ways. For example, Frontiers originally defended the special issues, saying that they were intended to give junior researchers an outlet to publish their ideas. Fair enough, and the spam issues have largely ceased. Still, I would argue it is the build up and repetition of these issues that has made authors and readers wary of the journal. This coupled with the high fees and feeling of automation leads to a perception that the outlet is mostly junk. This is a shame as there are certainly many high-value articles in Frontiers outlets. Nevertheless, academics are extremely bloodshy, and negative press creates a vicious feedback loop. If researchers feel Frontiers is a low-quality, spam-generating publisher who relies on overly automated processes, they are unlikely to submit their best work or review there. The quality of both drops, and the cycle intensifies.For my part, I don’t intend to return to Frontiers unless they begin publishing reviews. I think this would go a long way to stemming many of these issues and encourage authors to judge individual articles on their own merits.
What do you think? What can be done to stem the tide? Please add your own thoughts, and stories of positive or negative experiences at Frontiers, in the comments.
Edit:
A final comparison question
.@neuroconscience @lakens I should also run control: Which fancydancy high IF journal publishes the most rubbish? 😛
— Sam Schwarzkopf (@sampendu) January 15, 2016
- Short post – my science fiction vision of how science could work in the future

Sadly I missed the recent #isScienceBroken event at UCL, which from all reports was a smashing success. At the moment i’m just terribly focused on finishing up a series of intensive behavioral studies plus (as always) minimizing my free energy, so it just wasn’t possible to make it. Still, a few were interested to hear my take on things. I’m not one to try and commentate an event I wasn’t at, so instead i’ll just wax poetic for a moment about the kind of Science future i’d like to live in. Note that this has all basically been written down in my self-published article on the subject, but it might bear a re-hash as it’s fun to think about. As before, this is mostly adapted from Clay Shirky’s sci-fi vision of a totally autonomous and self-organizing science.
Science – OF THE FUTURE!
Our scene opens in the not-too distant future, say the year 2030. A gradual but steady trend towards self-publication has lead to the emergence of a new dominant research culture, wherein the vast majority of data first appear as self-archived digital manuscripts containing data, code, and descriptive-yet-conservative interpretations on centrally maintained, publicly supported research archives, prior to publication in traditional journals. These data would be subject to fully open pre-and post-publication peer review focused solely on the technical merit and clarity of the paper.
Having published your data in a totally standardized and transparent format, you would then go on write something more similar to what we currently formulate for high impact journals. Short, punchy, light on gory data details and heavy on fantastical interpretations. This would be your space to really sell what you think makes those data great – or to defend them against a firestorm of critical community comments. These would be submitted to journals like Nature and Science who would have the strictly editorial role of evaluating cohesiveness, general interest, novelty, etc. In some cases, those journals and similar entities (for example, autonomous high-reputation peer reviewing cliques) would actively solicit authors to submit such papers based on the buzz (good or bad) that their archived data had already generated. In principle multiple publishers could solicit submissions from the same buzzworthy data, effectively competing to have your paper in their journal. In this model, publishers must actively seek out the most interesting papers, fulfilling their current editorial role without jeopardizing crucial quality control mechanisms.
Is this crazy? Maybe. To be honest I see some version of this story as almost inevitable. The key bits and players may change, but I truly believe a ‘push-to-repo’ style science is an inevitable future. The key is to realize that even journals like Nature and Science play an important if lauded role, taking on editorial risk to highlight the sexiest (and least probable) findings. The real question is who will become the key players in shaping our new information economy. Will today’s major publishers die as Blockbuster did – too tied into their own profit schemes to mobilize – or will they be Netflix, adapting to the beat of progress? By segregating the quality and impact functions of publication, we’ll ultimately arrive at a far more efficient and effective science. The question is how, and when.
note: feel free to point out in the comments examples of how this is already becoming the case (some are already doing this). 30 years is a really, really conservative estimate 🙂
- MOOC on non-linear approaches to social and cognitive sciences. Votes needed!
My colleagues at Aarhus University have put together a fascinating proposal for a Massive Online Open Course (MOOC) on “Analyzing Behavioral Dynamics: non-linear approaches to social and cognitive sciences”. I’ve worked with Riccardo and Kristian since my masters and I can promise you the course will be excellent. They’ve spent the past 5 years exhaustively pursuing methodology in non-linear dynamics, graph theoretical, and semantic/semiotic analyses and I think will have a lot of interesting practical insights to offer. Best of all the course is free to all, as long as it gets enough votes on the MPF website. I’ve been a bit on the fence regarding my feelings about MOOCs, but in this case I think it’s really a great opportunity to give novel methodologies more exposure. Check it out- if you like it, give them a vote and consider joining the course!
Course Description
In the last decades, the social sciences have come to confront the temporal nature of human behavior and cognition: How do changes of heartbeat underlie emotions? How do we regulate our voices in a conversation? How do groups develop coordinative strategies to solve complex problems together?
This course enables you to tackle this sort of questions: addresses methods of analysis from nonlinear dynamics and complexity theory, which are designed to find and characterize patterns in this kind of complicated data. Traditionally developed in fields like physics and biology, non-linear methods are often neglected in social and cognitive sciences.The course consists of two parts:
The dynamics of behavior and cognition
In this part of the course you are introduced some examples of human behavior that challenge the assumptions of linear statistics: reading time, voice dynamics in clinical populations, etc. You are then shown step-by-step how to characterize and quantify patterns and temporal dynamics in these behaviors using non-linear methods, such as recurrence quantification analysis.
The dynamics of interpersonal coordination
In this second part of the course we focus on interpersonal coordination: how do people manage to coordinate action, emotion and cognition? We consider several real-world cases: heart beat synchronization during firewalking rituals, voice adaptation during conversations, joint problem solving in creative tasks – such as building Lego models together. You are then shown ways to analyze how two or more behaviors are coordinated and how to characterize their coupling – or lack-thereof.
This course provides a theoretical and practical introduction to non-linear techniques for social and cognitive sciences. It presents concrete case studies from actual research projects on human behavior and cognition. It encourages you to put all this to practice via practical exercises and quizzes. By the end of this course you will be fully equipped to go out and do your own research projects applying non-linear methods on human behavior and coordination.Learning objectives
Given a timeseries (e.g. a speech recording, or a sequence of reaction times), characterize its patterns: does it contain repetitions? How stable? How complex?
Given a timeseries (e.g. a speech recording, or a sequence of reaction times), characterize how it changes over time.
Given two timeseries (e.g. the movements of two dancers) characterize their coupling: how do they coordinate? Do they become more similar over time? Can you identify who is leading and who is following?
MOOC relevance
Social and cognitive research is increasingly investigating phenomena that are temporally unfolding and non-linear. However, most educational institutions only offer courses in linear statistics for social scientists. Hence, there is a need for an easy to understand introduction to non-linear analytical tools in a way that is specifically aimed at social and cognitive sciences. The combination of actual cases and concrete tools to analyze them will give the course a wide appeal.
Additionally, methods oriented courses on MOOC platforms such as Coursera have generally proved very attractive for students.Please spread the word about this interesting course!
- Quick post – Dan Dennett’s Brain talk on Free Will vs Moral Responsibility
As a few people have asked me to give some impression of Dan’s talk at the FIL Brain meeting today, i’m just going to jot my quickest impressions before I run off to the pub to celebrate finishing my dissertation today. Please excuse any typos as what follows is unedited! Dan gave a talk very similar to his previous one several months ago at the UCL philosophy department. As always Dan gave a lively talk with lots of funny moments and appeals to common sense. Here the focus was more on the media activities of neuroscientists, with some particularly funny finger wagging at Patrick Haggard and Chris Frith. Some good bits where his discussion of evidence that priming subjects against free will seems to make them more likely to commit immoral acts (cheating, stealing) and a very firm statement that neuroscience is being irresponsible complete with bombastic anti-free will quotes by the usual suspects. Although I am a bit rusty on the mechanics of the free will debate, Dennett essentially argued for a compatiblist view of free will and determinism. The argument goes something like this: the basic idea that free will is incompatible with determinism comes from a mythology that says in order to have free will, an agent must be wholly unpredictable. Dennett argues that this is absurd, we only need to be somewhat unpredictable. Rather than being perfectly random free agents, Dennett argues that what really matters is moral responsibility pragmatically construed. Dennett lists a “spec sheet” for constructing a morally responsible agent including “could have done otherwise, is somewhat unpredictable, acts for reasons, is subject to punishment…”. In essence Dan seems to be claiming that neuroscientists don’t really care about “free will”, rather we care about the pragmatic limits within which we feel comfortable entering into legal agreements with an agent. Thus the job of the neuroscientists is not to try to reconcile the folk and scientific views of “free will”, which isn’t interesting (on Dennett’s acocunt) anyway, but rather to describe the conditions under which an agent can be considered morally responsible. The take home message seemed to be that moral responsibility is essentially a political rather than metaphysical construct. I’m afraid I can’t go into terrible detail about the supporting arguments- to be honest Dan’s talk was extremely short on argumentation. The version he gave to the philosophy department was much heavier on technical argumentation, particularly centered around proving that compatibilism doesn’t contradict with “it could have been otherwise”. In all the talk was very pragmatic, and I do agree with the conclusions to some degree- that we ought to be more concerned with the conditions and function of “will” and not argue so much about the meta-physics of “free”. Still my inner philosopher felt that Dan is embracing some kind of basic logical contradiction and hand-waving it away with funny intuition pumps, which for me are typically unsatisfying.
For reference, here is the abstract of the talk:
Nothing—yet—in neuroscience shows we don’t have free will
Contrary to the recent chorus of neuroscientists and psychologists declaring that free will is an illusion, I’ll be arguing (not for the first time, but with some new arguments and considerations) that this familiar claim is so far from having been demonstrated by neuroscience that those who advance it are professionally negligent, especially given the substantial social consequences of their being believed by lay people. None of the Libet-inspired work has the drastic implications typically adduced, and in fact the Soon et al (2008) work, and its descendants, can be seen to demonstrate an evolved adaptation to enhance our free will, not threaten it. Neuroscientists are not asking the right questions about free will—or what we might better call moral competence—and once they start asking and answering the right questions we may discover that the standard presumption that all “normal” adults are roughly equal in moral competence and hence in accountability is in for some serious erosion. It is this discoverable difference between superficially similar human beings that may oblige us to make major revisions in our laws and customs. Do we human beings have free will? Some of us do, but we must be careful about imposing the obligations of our good fortune on our fellow citizens wholesale.